こんにちは。配信/インフラチームの佐々木です。
弊社ではAWS上にシステムを構築していますが、前回お話しした通り監視ツールはCloudWatchを利用するケースが増えております。 今回はAPIを利用してCloudWatchを設定する手順をご説明します。
Alarmの設定
CloudWatchの用途としてインスタンスの監視に使うケースは多いと思います。そこでインスタンスのAlarmを設定するスクリプトを作ってみました。aws-cliとbotoどちらかを利用するのですが、今回はaws-cliで実装しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
#!/usr/bin/env python import subprocess import sys instance_list = sys.argv[1:] for i in instance_list: instance_id = subprocess.check_output("aws ec2 describe-instances --filters Name=tag-key,Values=Name,Name=tag-value,Values=" + i + " --query 'Reservations[].Instances[].InstanceId' --output text", shell=True) instance_id = instance_id.strip() put_metric_alarm = 'aws cloudwatch put-metric-alarm --alarm-name awsec2-' + i + '-Status --comparison-operator GreaterThanOrEqualToThreshold \ --threshold 1 \ --metric-name StatusCheckFailed \ --evaluation-periods 1 \ --period 60 \ --namespace "AWS/EC2" \ --statistic Maximum \ --dimensions Name=InstanceId,Value=' + instance_id + ' \ --alarm-actions XXXXXXXXXX' subprocess.check_output(put_metric_alarm , shell=True) |
このように引数にNameタグを指定して利用します。
|
1 |
$ python cloudwatch.py WEB-01 WEB-02 ... |
インスタンスIDで指定する方がシンプルな実装になるのですが、インスタンスIDはコピーペーストする必要がありますし、Nameタグの方がワイルドカード指定も出来て便利です。またアラーム名にもNameタグが入っていた方わかりやすくて良いと思います。ただNameタグが一意である必要がありますのでその点は注意が必要です。
Dashboardの設定
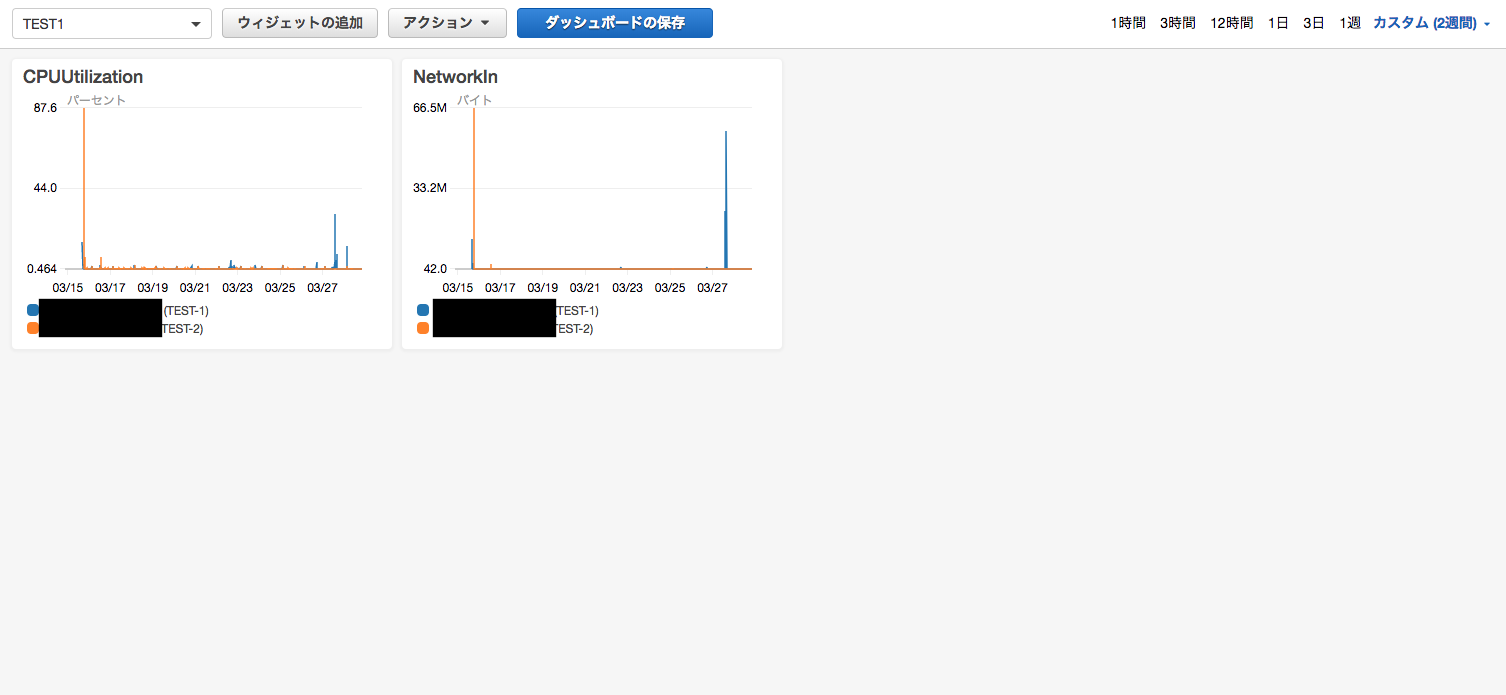
CloudWatchのDashboardもAPIを利用して設定することが可能です。その手順を記載します。
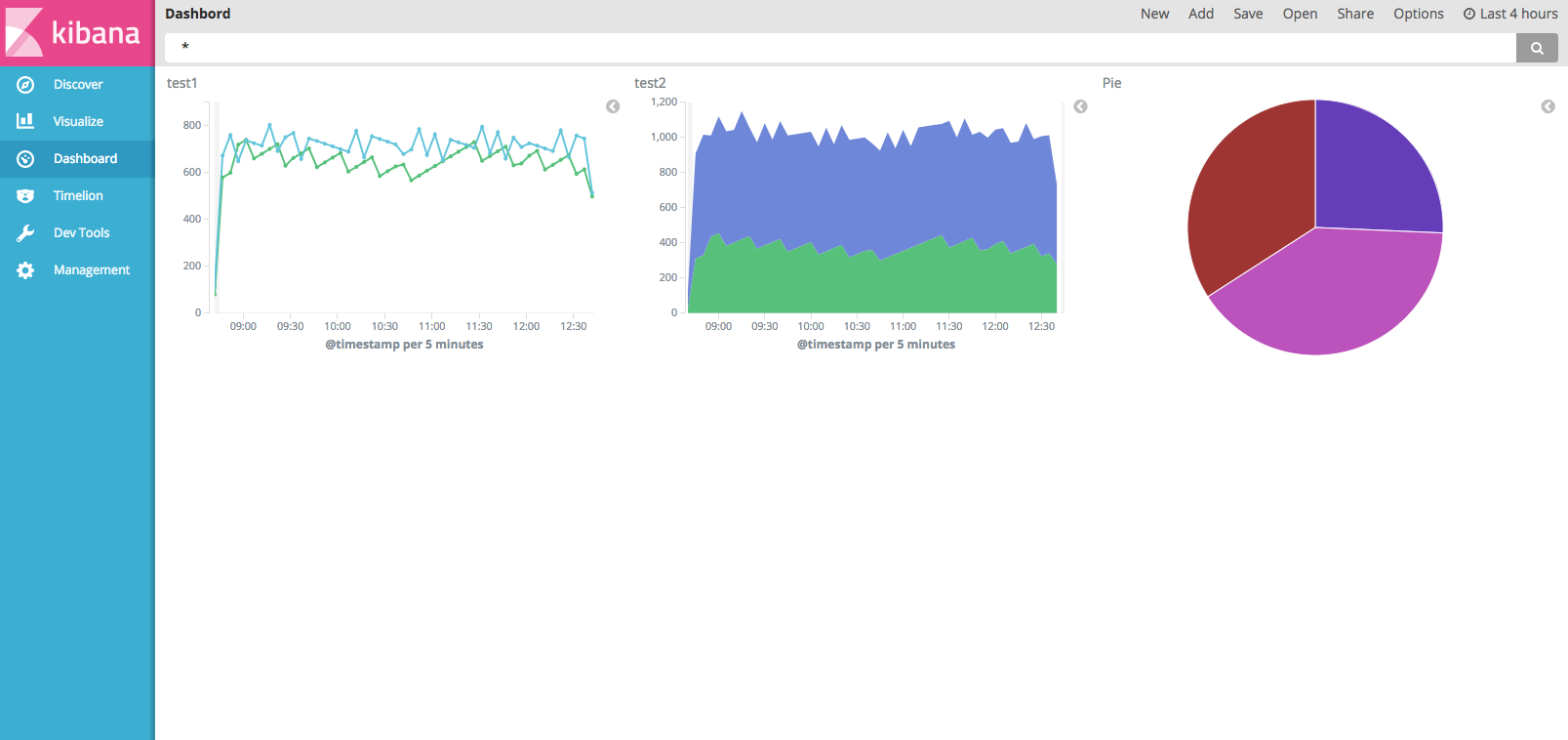
APIの仕様は以下になるのですが、元になる設定が無いと難しいと思いますので、適当なDashboardから定義をコピーします。ここでは2台のインスタンスのCPU使用率とNetworkInのメトリックを登録しています。
https://docs.aws.amazon.com/AmazonCloudWatch/latest/APIReference/API_PutDashboard.html
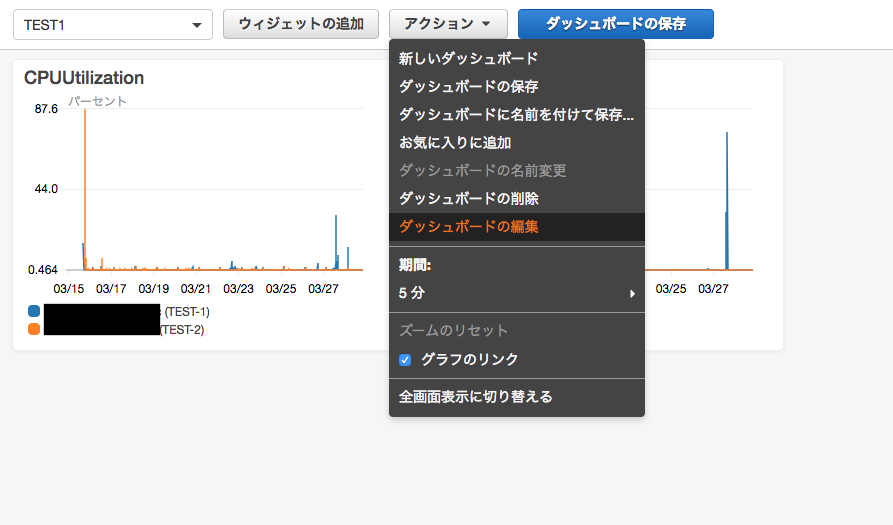
[アクション]の[ダッシュボードの編集]を選択すると、Jsonの定義を取得できます。ここから直接変更することも可能です。
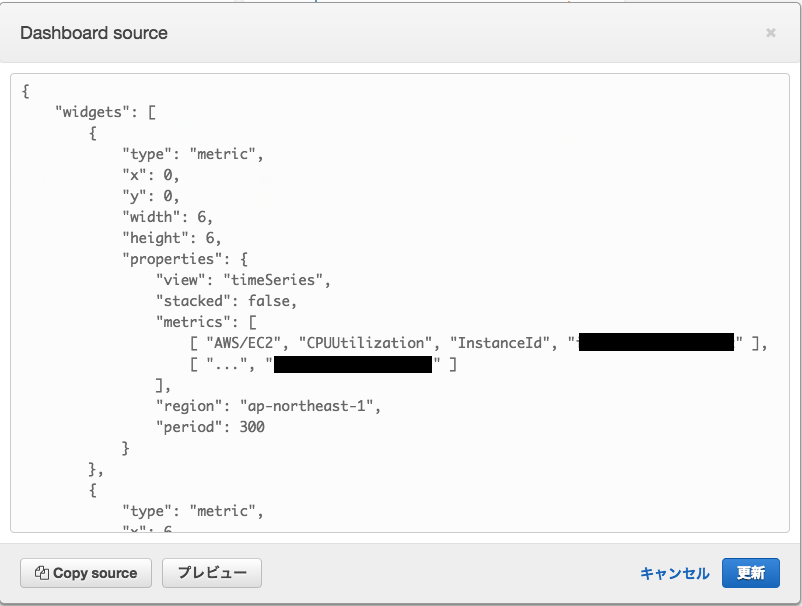 コピーしたJsonを元に編集します。インスタンスを1台増やしてサイズも倍にしてみました。
コピーしたJsonを元に編集します。インスタンスを1台増やしてサイズも倍にしてみました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
{ "widgets": [ { "type": "metric", "x": 0, "y": 0, "width": 12, "height": 12, "properties": { "view": "timeSeries", "stacked": false, "metrics": [ [ "AWS/EC2", "CPUUtilization", "InstanceId", "XXXXXXXXXX" ], [ "...", "XXXXXXXXXX" ], [ "...", "XXXXXXXXXX" ] ], "region": "ap-northeast-1", "period": 300 } }, { "type": "metric", "x": 12, "y": 0, "width": 12, "height": 12, "styles": "undefined", "properties": { "view": "timeSeries", "stacked": false, "region": "ap-northeast-1", "metrics": [ [ "AWS/EC2", "NetworkIn", "InstanceId", "XXXXXXXXXX" ], [ "...", "XXXXXXXXXX" ], [ "...", "XXXXXXXXXX" ] ] } } ] } |
作成したJsonファイルを以下のコマンドで適用します。
|
1 |
$ aws cloudwatch put-dashboard --dashboard-name TEST2 --dashboard-body file://dashbord.json |
完成しました。

またこちらのページに、複数インスタンスを自動で登録するスクリプトが載っております。台数や取得するパラメータが多い場合などにはかなり有用かと思います。
今回は以上になります。