こんにちは。配信/インフラチームの佐々木です。 今回は、adstirの集計システムをHadoopからSparkに移行したお話をしたいと思います。
以前の構成
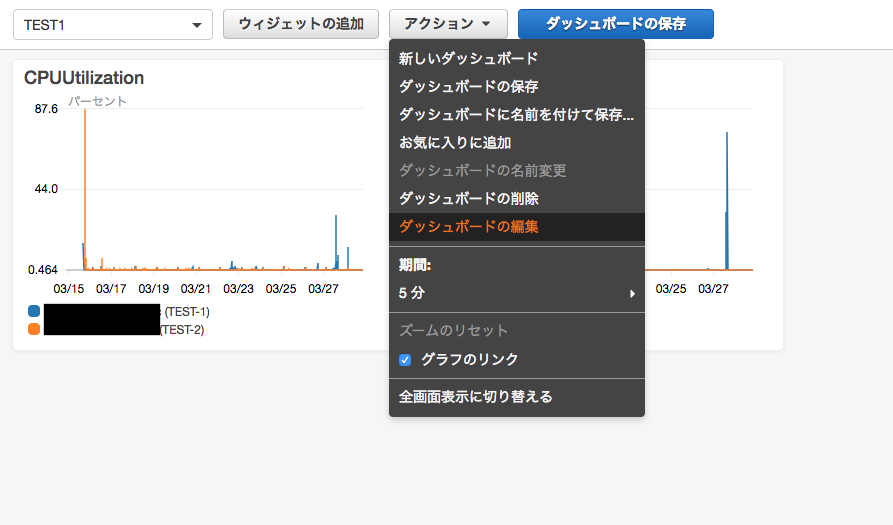
adstirでは以前はAWS上のEMRでHadoopを使って集計していました。一つの集計のフローとしては以下のようになります。
Mapper(UNIQ集計)
↓
SQSにメッセージを送信
↓
Reducer(UNIQ集計)
↓
SQSにメッセージを送信
↓
Mapper(通常集計)
↓
SQSにメッセージを送信
↓
Reducer(通常集計)
このシステムでは以下のような問題点があり、それを解消するために移行を計画しました。
・Hadoopのパフォーマンスがあまり良くなく、集計に時間がかかり、かつ料金的なコストもかかる。
・MapperとReducerでアプリケーションがを分ける必要があり、UNIQ集計も別で必要になるため、煩雑な仕組みになる。
・かなり昔に開発したシステムの為、利用しているサービスや構成が古く、パフォーマンス・安定性等お世辞にも良いと言えない為、最新のアーキテクチャに刷新したい。
Sparkに移行すれば、UNIQ集計を分ける必要もなく、SQSでの通知も不要になります。つまり上記のフローが一つの処理で完結するわけで、システムが大幅に簡素化し、かつ時間短縮・コスト削減するのを見込み開発をしました。
移行する集計用のソフトウェアの検討
当初はAthenaに移行する想定でしたが、Athenaは分析用のサービスで、今回のようなバッチでの集計処理には向いていないことがわかり、Hadoopから移行しやすくかつパフォーマンスの良いSparkを採用することにしました。 ですが手動での分析ではAthenaを使いたいとの要望があり、バッチ集計をSpark、分析用にAthenaを使い分けをするようにしました。
Sparkについて
Sparkとは一言で言えば「オンメモリで動くHadoop」の事で、AWSではEMRでのマネージドサービスを使うことが出来ます。 利用できる言語はScala、Python、R、Java等ですが一般的にはScalaとPythonを使うことが多いようです。Spark自体はScalaで実装されています。
採用した言語とAPI
当初はPythonで実装したのですが、テストしてみたところHadoopとあまりパフォーマンスが変わりませんでした。原因はRDDでの処理がボトルネックになっている事でした。 Sparkで使える用意されているAPIはRDD、Dataframe、Datasetの3種類があります。APIの特徴は以下のページに詳しく書かれています。
https://yubessy.hatenablog.com/entry/2016/12/11/095915 https://databricks.com/blog/2015/02/17/introducing-dataframes-in-spark-for-large-scale-data-science.html
一見PythonでDataframeを使うのが良さそうなのですが、Dataframeは色々制限がある為、複雑なデータ構造を扱う場合はRDDの方が向いています。 そこで全てScalaに書き換え、APIにRDDとDataframeを併用する実装にしました。 またSparkはExecuter(分散)とDriver(非分散)で処理が分かれており、できる限りExecuter側で処理をすればパフォーマンスが向上しますので、そこを意識して実装する事が大事でした。
結果
集計時間とコストが1/3程度になり、期待する結果を得る事が出来ました。 AWSでは集計用のマネージドサービスが他にも多々あり、これからも追加されていくと思われますので、今後もキャッチアップして行きたいと思います。
今回は以上となります。